PDFや画像ファイルをドラッグするだけで
文字を抽出できるWebサービス。
無料でアカウント不要ですぐに使うことができ
日本語も認識することができます。
目次
リンク先
OCR PDFs and images directly in your browser リンク先はこちらから
使い方
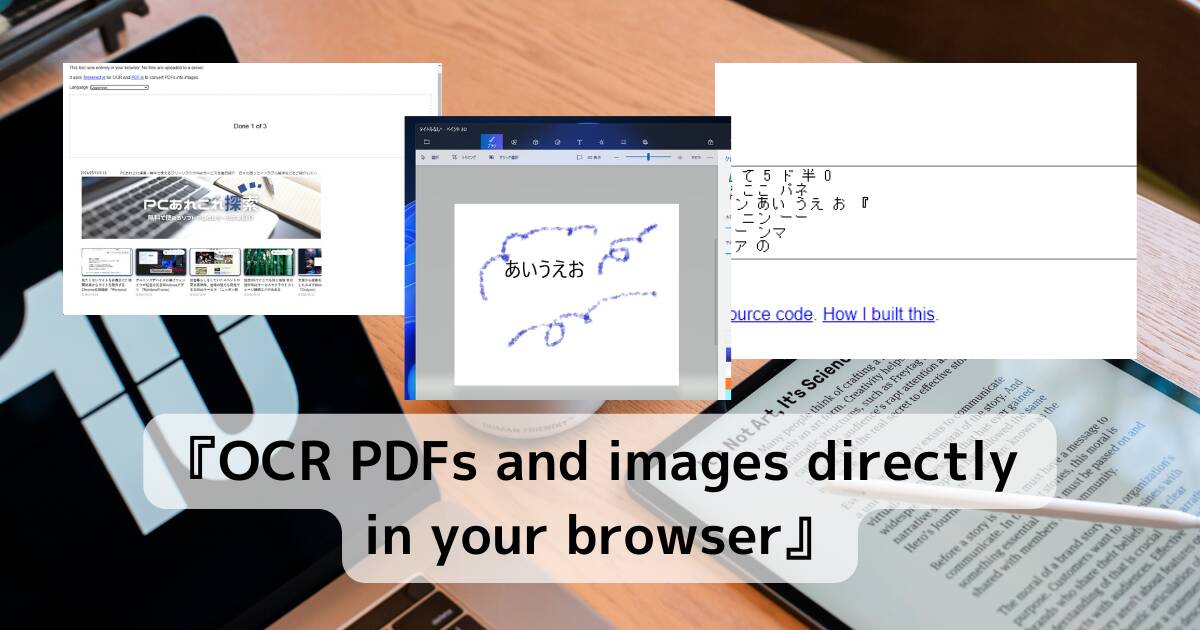
上記リンク先ページを開くと、かなりシンプルな画面が表示されます。
アカウント不要ですぐに使うことができます。
まずはLanguageからJapaneseで日本語を認識できるように選択します。
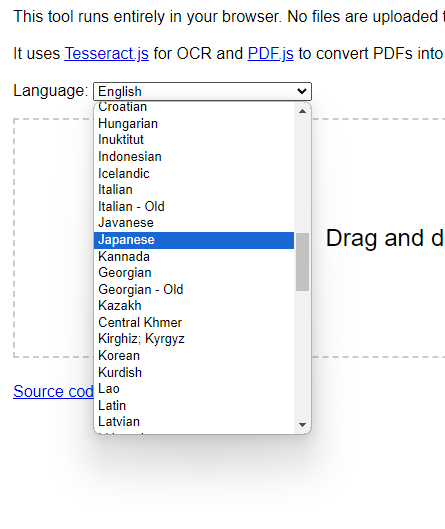
ここからJapaneseを選択します。
他にもたくさんの言語が選択可能です。
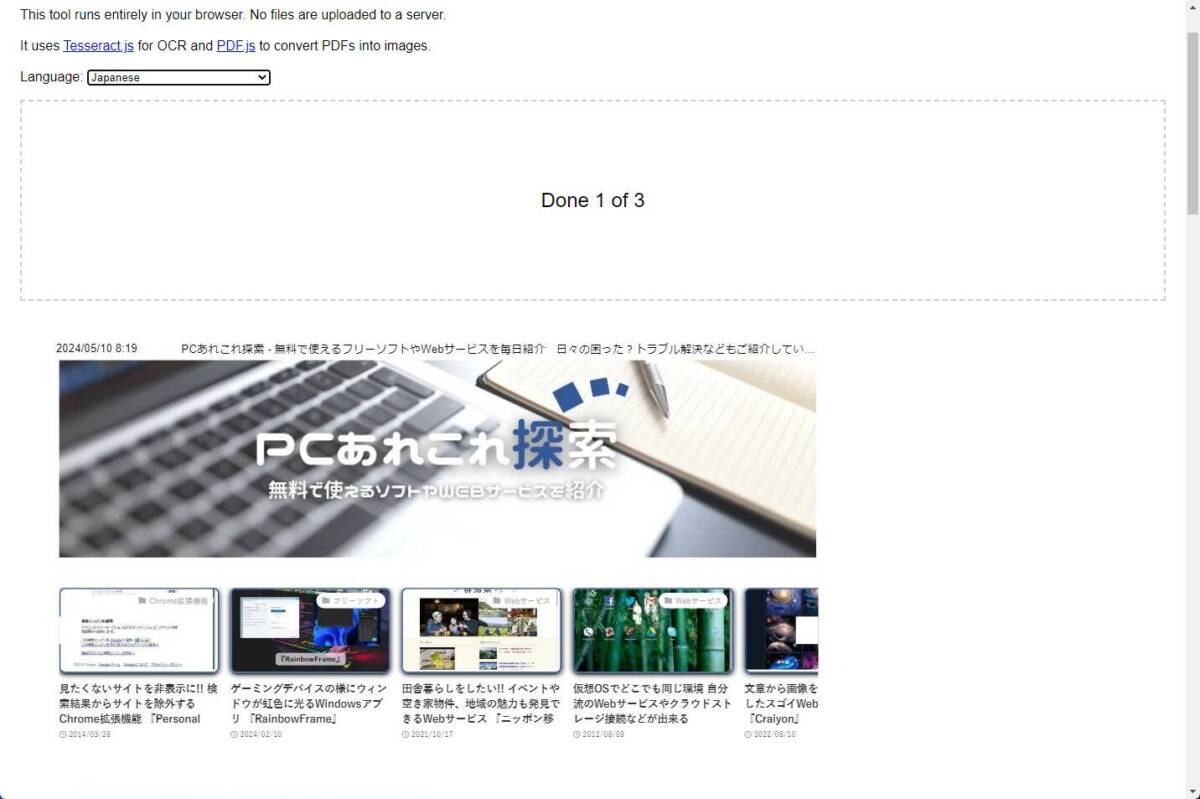
このブログをPDFに印刷して読み込ませてみました。
しばらくするとDoneと表示されOCR解析が終わったことが表示されます。

各ページ毎にFull documentと表示されページ内の文字が認識しています。
精度としてはまずまずな感じですが、概ね認識しています。
次はこんな画像を読み込ませてみました。
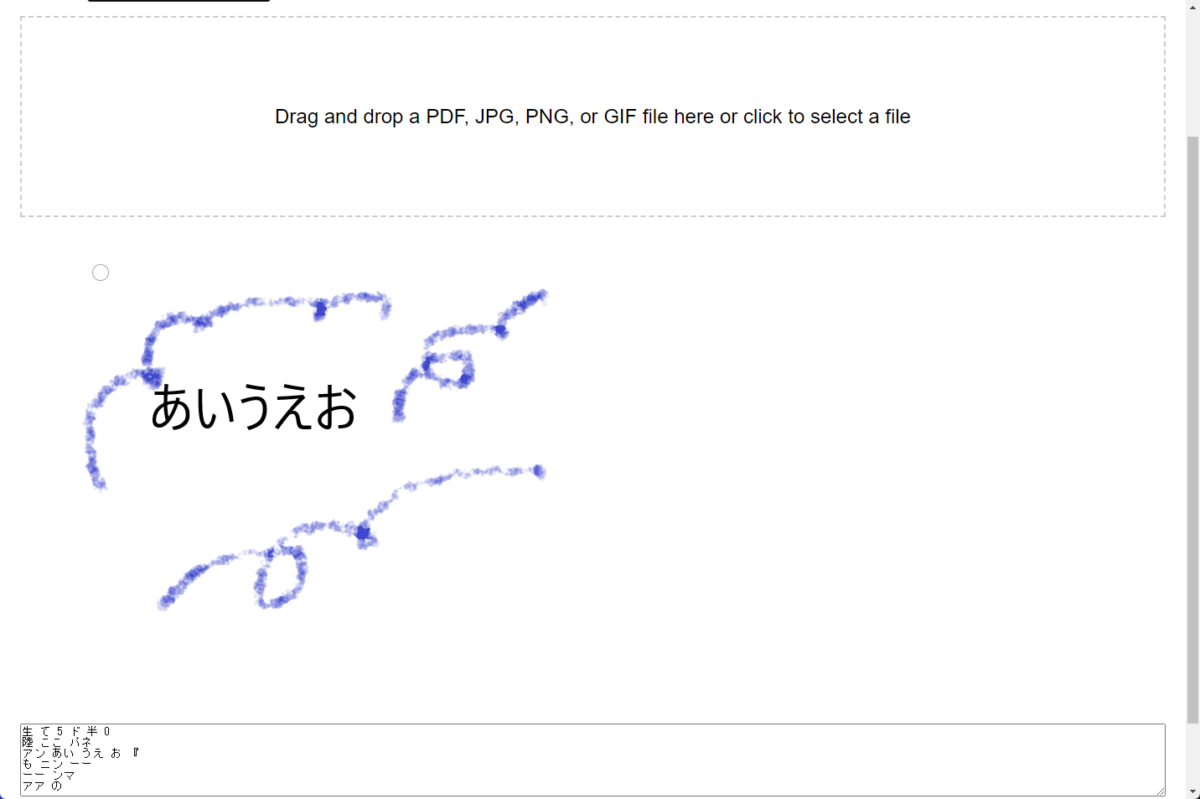
文字ではないフリーペンの所も認識して文字として表示されています。
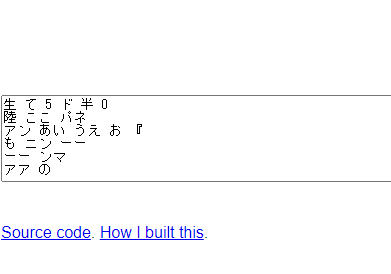
精度はまずまずと言ったところでしょうか。PDFや画像などの品質やフォントなどにも
大きく左右されそうですが、画像などから文字認識してコピーしたい場合などには
使えるかもしれません。


コメント